
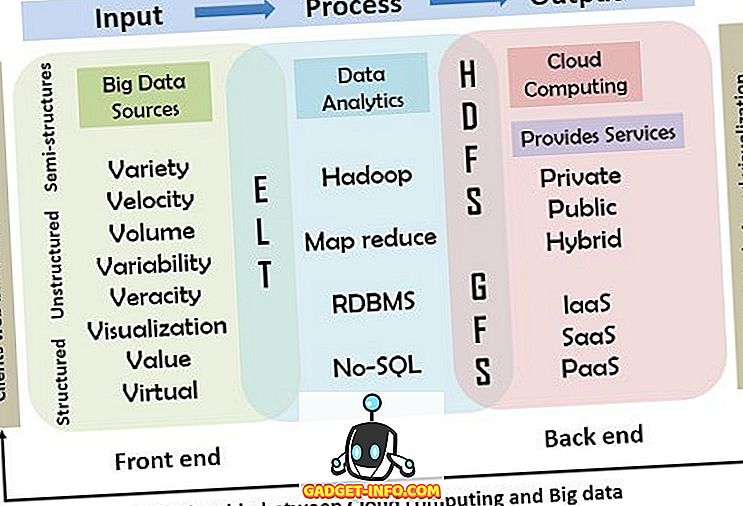
See hõlmab sisend-, töötlemis- ja väljundmudelit, mida selgitatakse allpool; skeem illustreerib pilvandmetöötluse ja suurte andmete vahelist seost üksikasjalikult.
Võrdluskaart
| Võrdluse alus | Pilvandmetöötlus | Suured andmed |
|---|---|---|
| Põhiline | Tellitavaid teenuseid osutatakse integreeritud arvutiressursside ja süsteemide abil. | Ulatuslik kogum struktureeritud, struktureerimata ja keerulisi andmeid, mis keelavad traditsioonilise töötlemismeetodi töötada. |
| Eesmärk | Võimaldab salvestada ja töödelda andmeid serveris ja pääseda mis tahes kohas. | Suurte andmemahtude ja informatsiooni korraldamine ekstraktile on varjatud väärtuslikke teadmisi. |
| Töötamine | hajutatud andmetöötlust kasutatakse andmete analüüsimiseks ja kasulikumate andmete saamiseks. | Internetti kasutatakse pilvepõhiste teenuste pakkumiseks. |
| Eelised | Madalad hoolduskulud, tsentraliseeritud platvorm, varukoopia ja taastamine. | Tasuv paralleelsus, skaleeritav, tugev. |
| Väljakutsed | Kättesaadavus, ümberkujundamine, turvalisus, laadimismudel. | Andmete sort, andmete salvestamine, andmete integreerimine, andmetöötlus ja ressursside haldamine. |
Pilvandmetöötluse määratlus
Pilvandmetöötlus pakub integreeritud teenuste platvormi, et salvestada ja hankida mis tahes andmeid mis tahes ajal, igal pool nõudmisel, kasutades kiiret internetiühendust. Cloud on ulatuslik maapealse serveri hulk, mis on hajutatud üle interneti andmete salvestamiseks, haldamiseks ja töötlemiseks. Pilvandmetöötlus on välja töötatud nii, et arendajad saaksid veebipõhist arvutit hõlpsasti rakendada. Interneti areng on toonud pilvandmetöötluse mudeli, kuna internet on pilvandmetöötluse aluseks. Pilvandmetöötluse tõhusaks toimimiseks on vaja kiiret internetiühendust. See pakub paindlikku keskkonda, kus võimsust ja võimeid saab lisada dünaamiliselt ja kasutada vastavalt tasule kasutamise strateegiale.
Pilvandmetöötlusel on mõned olulised omadused, milleks on ressursside ühendamine, tellitavad iseteenindus, laialdane juurdepääs võrgule, mõõdetud teenus ja kiire elastsus. Pilve on nelja tüüpi - avalik, era-, hübriid- ja kogukond.
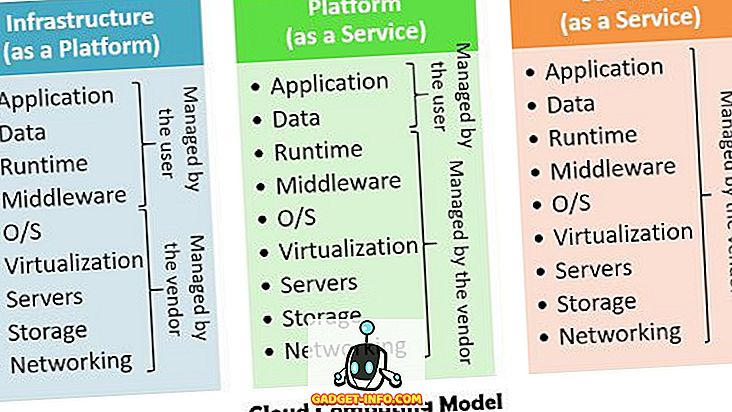
Põhimõtteliselt on kolm pilvandmetöötluse mudelit - platvorm kui teenus (Paas), infrastruktuur kui teenus (Iaas), tarkvara kui teenus (Saas), mis kasutab nii riistvara kui ka tarkvarateenuseid.
- Infrastruktuur kui teenus - seda teenust kasutatakse infrastruktuuri edastamiseks, mis hõlmab salvestusjõudu ja virtuaalmasinaid. See rakendab ressursside virtualiseerimist teenustaseme kokkuleppe (SLA) alusel.
- Platvorm kui teenus - see on IaaS-i kihi kohal, mis pakub programmeerimis- ja ajastuskeskkonda, et kasutajad saaksid pilvrakendusi kasutada.
- Tarkvara kui teenus - see edastab rakendused kliendile, kes töötab otse pilveteenuse pakkujal.

Suurandmete määratlus
Andmed muutuvad suurandmeteks, suurendades mahtu, mitmekesisust, kiirust, väljaspool IT-süsteemide võimeid, mis omakorda tekitavad raskusi andmete salvestamisel, analüüsimisel ja töötlemisel. Mõned organisatsioonid on välja töötanud sellise massiivse koguse struktureeritud andmetega tegelemiseks vajaliku varustuse ja asjatundlikkuse, kuid eksponentsiaalselt kasvavad mahud ja kiire andmevoog lõpetavad võime seda kaevata ja tekitada operatiivset luure kiiresti. Neid mahukaid andmeid ei saa tavalistes seadmetes salvestada ja hajutatud keskkonnas hajutada. Suurte andmetöötlus on andmete teaduse esialgne kontseptsioon, mis keskendub mitmemõõtmelisele teabe hankimisele teadusliku avastamise ja suurte infrastruktuuride ärianalüütika jaoks.
Suurandmete põhimõõtmed on maht, kiirus, sort ja õigsus, mis on samuti ülalmainitud, hiljem on välja kujunenud veel kaks dimensiooni, mis on varieeruvus ja väärtus.
- Helitugevus - tähistab kasvavat andmemahu, mis on juba probleemseks selle töötlemiseks ja salvestamiseks.
- Kiirus - see on näide, kus andmed on salvestatud ja andmete kiirus.
- Sordid - Andmed ei esine alati ühes vormis, on mitmesuguseid andmeid, näiteks teksti, heli, pilti ja videot.
- Usaldusväärsus - seda nimetati andmete usaldusväärsuseks.
- Muutlikkus - kirjeldatakse suurandmetes koostatud usaldusväärsust, keerukust ja vastuolusid.
- Väärtus - sisu algne vorm ei pruugi olla palju kasulik ja produktiivne, nii et andmeid analüüsitakse ja avastatakse kõrge väärtusega andmed.
Peamised erinevused pilvandmetöötluse ja suurandmete vahel
- Pilvandmetöötlus on arvutipõhine teenus, mida pakutakse interneti kaudu hajutatud arvutusressursside abil. Teisest küljest on suured andmed arvukad arvutiandmed, sealhulgas struktureeritud, struktureerimata, poolstruktureeritud andmed, mida ei saa töödelda traditsiooniliste algoritmide ja tehnikatega.
- Pilvandmetöötlus annab kasutajatele võimaluse kasutada teenuseid nagu Saas, Paas ja Iaas nõudmisel ja tasub ka teenuse eest vastavalt kasutusele. Suurandmete peamine eesmärk on seevastu varjatud teadmiste ja mustrite kogumine andmete humongous kogumisest.
- Kiire internetiühendus on pilvandmetöötluse oluline nõue. Seevastu suurandmetes kasutatakse andmete analüüsimiseks ja kaevandamiseks hajutatud arvutit.
Pilvandmetöötluse ja suurte andmete vaheline seos
Alljärgnev diagramm illustreerib pilvandmetöötluse suhet ja tööd suurte andmetega. Selles mudelis kasutatakse esmase sisend-, töötlemis- ja väljundarvutimudeli viitena, milles suured andmed sisestatakse süsteemis, kasutades selliseid sisendseadmeid nagu hiir, klaviatuur, mobiiltelefonid ja muud nutikaseadmed. Töötlemise teine etapp hõlmab vahendeid ja meetodeid, mida pilv teenuste kasutamiseks pakub. Lõpuks saadetakse töötlemise tulemus kasutajatele.
Järeldus
Pilvandmetöötlustehnoloogia pakub suurte andmete jaoks sobivat ja ühilduvat raamistikku kasutamise lihtsuse, ressursside kättesaadavuse, pakkumise ja nõudluse ressursikasutuse madala hinna tõttu ning vähendab ka suurte andmete töötlemisel kasutatavate tahkete seadmete kasutamist. Nii pilve kui ka suured andmed rõhutavad ettevõtte väärtuse suurendamist, vähendades samal ajal investeerimiskulusid.